Разработка проекта “Электронный мозг”: AI-база знаний с GPT, почтой и голосовыми заметками, и индексация RAG-базы
Краткое описание проекта
Был разработан проект “Электронный мозг” — персональная AI-база знаний, которая собирает информацию из разных источников, обрабатывает её с помощью искусственного интеллекта и позволяет быстро находить нужные данные через диалог с GPT.
Идея проекта — создать единое место, куда автоматически попадают голосовые заметки, письма, документы и файлы. После обработки вся информация становится доступной для поиска, анализа и общения в формате обычного диалога.
Пользователь может не вспоминать, где именно была нужная информация: в голосовой заметке, письме, документе или файле на диске. Достаточно задать вопрос через GPT, и система найдёт нужный фрагмент в общей базе знаний.
Что умеет система
“Электронный мозг” подключает и обрабатывает несколько типов источников:
-
голосовые заметки с диктофона;
-
текстовые заметки;
-
электронную почту;
-
файлы и документы;
-
Яндекс.Диск;
-
данные, загруженные вручную через админку.
После загрузки данные проходят обработку, сохраняются в базе, индексируются и становятся доступны через AI-поиск.
Голосовые заметки
Один из главных сценариев проекта — работа с голосовыми заметками.
Пользователь может записывать мысли, идеи, задачи или итоги встреч на диктофон. Затем запись попадает в систему, где она:
-
Загружается в проект.
-
Преобразуется из аудио в текст.
-
Очищается и нормализуется.
-
Анализируется AI-моделью.
-
Разбивается на смысловые блоки.
-
Сохраняется в базу знаний.
-
Индексируется для поиска.
После этого по голосовой заметке можно задавать вопросы:
Что я говорил по проекту?
Какие задачи я поставил?
Какие решения были озвучены?
Найди заметку, где я говорил про клиента.
Таким образом, обычный диктофон превращается в инструмент накопления и структурирования знаний.
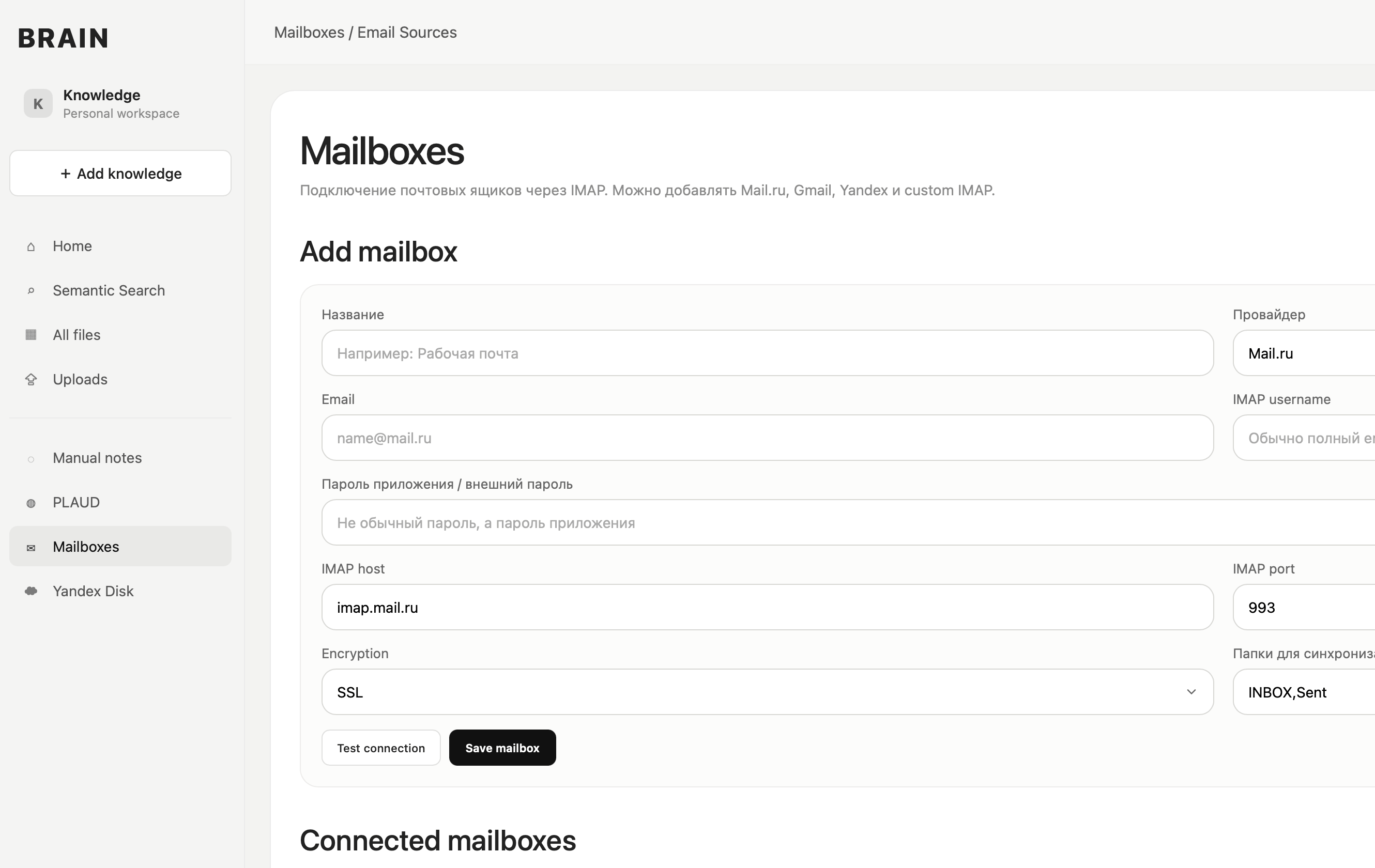
Подключение почты
В проект была добавлена возможность подключать почтовые ящики через IMAP.
Система может получать письма, сохранять их в базе и передавать содержимое в общий AI-обработчик. Это позволяет использовать email как полноценный источник знаний.
Например, в письмах часто хранятся:
-
договорённости с клиентами;
-
задачи;
-
счета;
-
вложения;
-
обсуждения проектов;
-
важные контакты;
-
история переписки.
После подключения почты пользователь может спрашивать:
Что писал клиент по последнему проекту?
Найди письмо про оплату.
Какие задачи были в переписке?
Что обсуждали с подрядчиком?
Для подключения почты реализованы настройки IMAP, проверка подключения, сохранение аккаунтов и фоновая синхронизация через очередь.
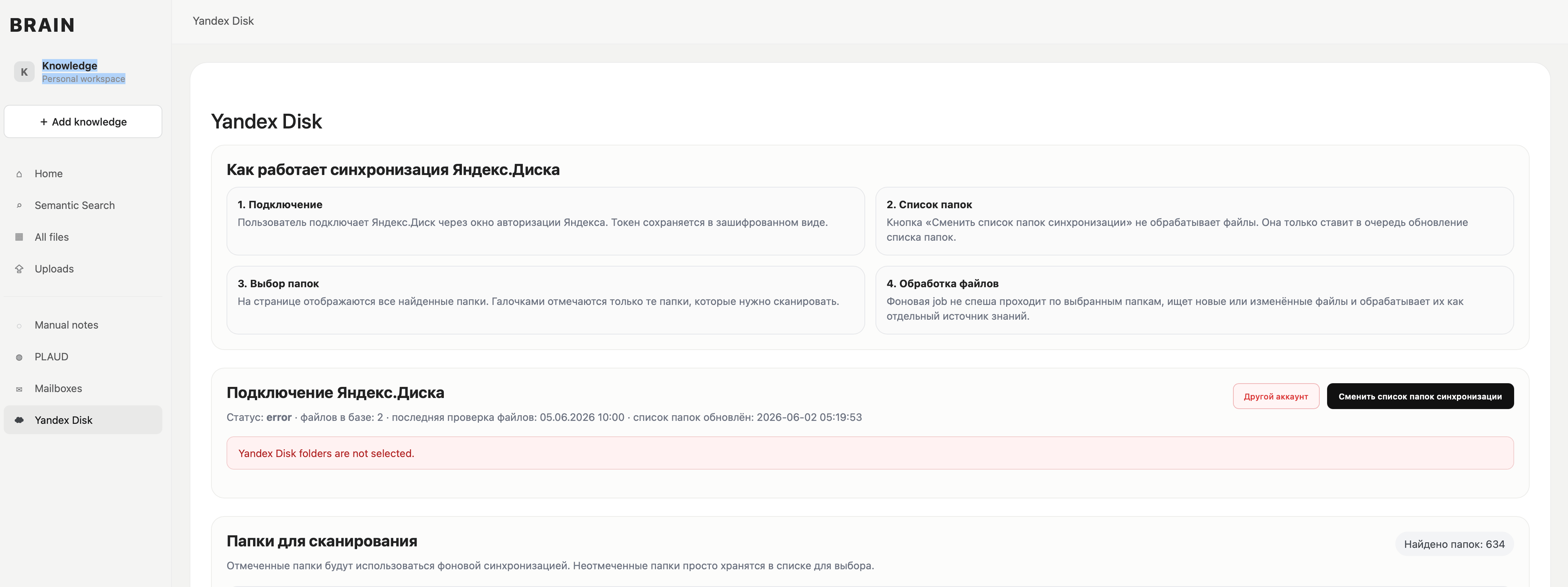
Интеграция с Яндекс.Диском
Также в проект была добавлена интеграция с Яндекс.Диском.
Система может получать список папок и файлов, подключать облачное хранилище как источник данных и использовать документы с диска для дальнейшей обработки.
Это удобно, когда важная информация уже хранится в облаке:
-
документы;
-
отчёты;
-
текстовые файлы;
-
PDF;
-
рабочие материалы;
-
архивы проектов.
После подключения Яндекс.Диска файлы можно загружать в систему, обрабатывать и добавлять в общую базу знаний.
Общение через GPT
Главное преимущество проекта — возможность общаться с базой знаний через GPT.
Пользователь не работает с обычным поиском по файлам. Он задаёт вопрос естественным языком:
Что я обсуждал по проекту на прошлой неделе?
Какие задачи есть по клиенту?
Найди информацию про оплату.
Что было в голосовой заметке про запуск?
Какие документы есть по этой теме?
GPT обращается к API проекта, получает релевантные записи из базы знаний и формирует ответ на основе найденной информации.
Таким образом, GPT становится интерфейсом к личной или корпоративной памяти.
Как устроена обработка данных
Внутри проекта реализован единый pipeline обработки информации.
Общая схема:
Источник данных → загрузка → обработка → анализ → сохранение → индексация → поиск через GPT
Источником может быть:
-
аудиофайл;
-
голосовая заметка;
-
email;
-
файл с Яндекс.Диска;
-
текстовый документ;
-
ручная заметка.
После попадания в систему данные приводятся к единому формату. Это позволяет работать с разными источниками одинаково.
AI-анализ и индексация
После загрузки данные обрабатываются AI-моделью.
Система может выделять:
-
краткое содержание;
-
важные факты;
-
задачи;
-
решения;
-
ключевые темы;
-
связи с другими материалами.
Далее текст разбивается на смысловые части и индексируется для семантического поиска.
Это позволяет искать информацию не только по точному совпадению слов, но и по смыслу.
Например, пользователь может спросить:
Где я говорил про запуск рекламы?
Даже если в исходном тексте не было точной фразы “запуск рекламы”, система может найти близкие по смыслу записи.
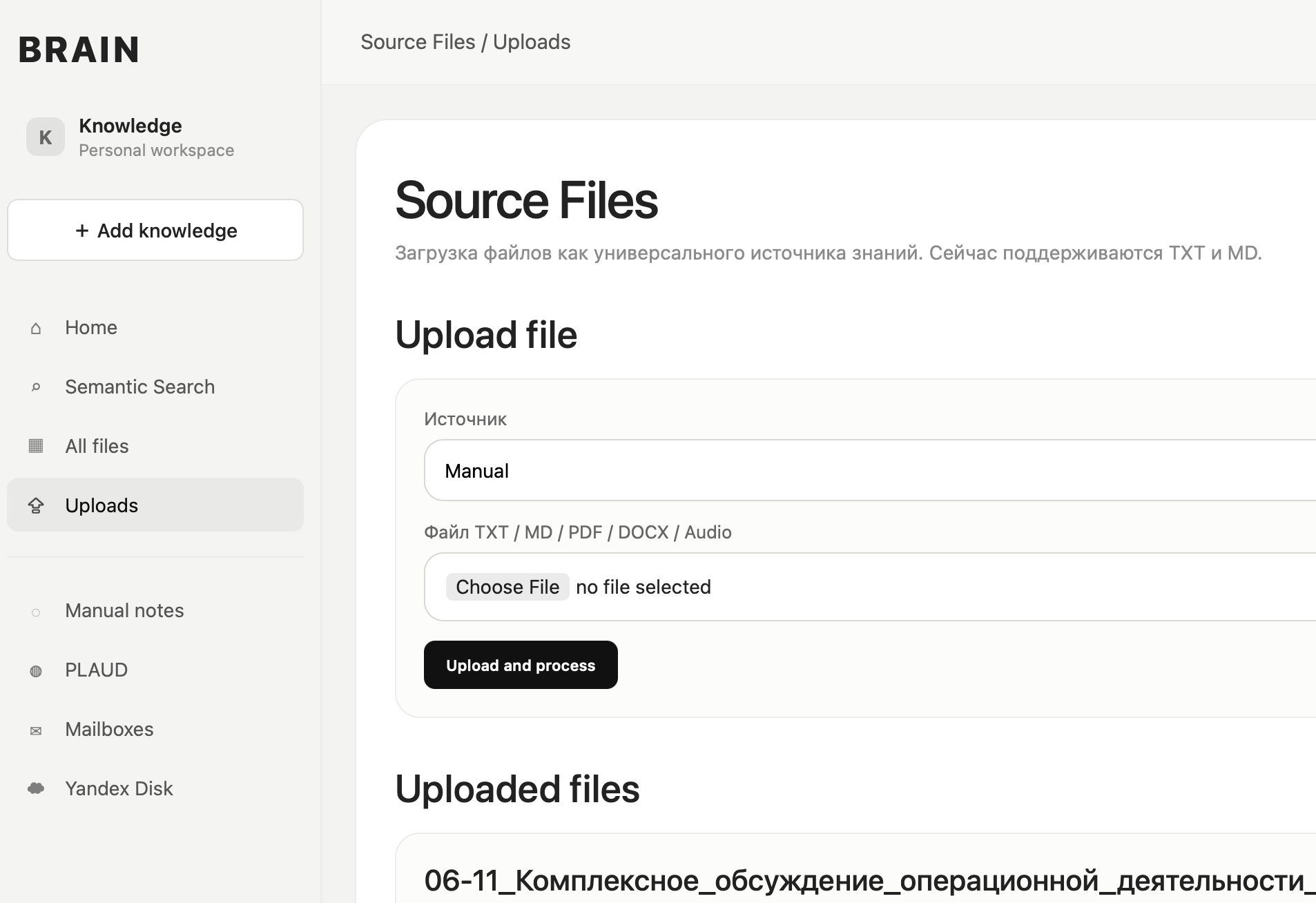
Административная панель
Для управления проектом была реализована админка.
В ней можно:
-
добавлять ручные заметки;
-
загружать аудиофайлы;
-
просматривать обработанные записи;
-
подключать почтовые ящики;
-
запускать синхронизацию почты;
-
подключать Яндекс.Диск;
-
обновлять список папок;
-
отслеживать ошибки обработки;
-
управлять источниками данных.
Админка нужна для настройки источников и контроля обработки, а основной пользовательский сценарий — общение через GPT.
Фоновая обработка через очереди
Так как обработка аудио, писем и файлов может занимать время, в проекте используется фоновая обработка через очереди.
Это позволяет не блокировать интерфейс. Пользователь загружает файл или запускает синхронизацию, а система ставит задачу в очередь и обрабатывает её в фоне.
Через очереди выполняются:
-
обработка голосовых заметок;
-
транскрибация аудио;
-
синхронизация почты;
-
обновление папок Яндекс.Диска;
-
AI-анализ;
-
индексация данных.
Безопасность
Так как проект работает с личными и рабочими данными, была предусмотрена базовая защита:
-
авторизация в админке;
-
хранение паролей почтовых ящиков в зашифрованном виде;
-
использование паролей приложений для почты;
-
закрытый API для GPT;
-
доступ к API по специальному ключу;
-
работа через HTTPS;
-
фоновая обработка без публичного доступа к внутренним сервисам.
Технологии проекта
В проекте использовались:
-
Laravel;
-
PHP;
-
MySQL;
-
Redis;
-
Laravel Queue;
-
Docker;
-
Nginx;
-
SSL;
-
OpenAI API;
-
Custom GPT Actions;
-
Qdrant;
-
IMAP;
-
Яндекс.Диск API;
-
обработка аудио;
-
семантический поиск;
-
RAG-подход.
Результат
В результате был создан проект “Электронный мозг” — AI-система для накопления и поиска знаний.
Проект умеет принимать информацию из разных источников, обрабатывать её, сохранять в структурированном виде и делать доступной через GPT.
Пользователь может записывать голосовые заметки, подключать почту, использовать файлы с Яндекс.Диска и затем обращаться к этой информации через обычный диалог.
Это превращает разрозненные данные в единую интеллектуальную базу знаний.
Практическая польза
Такой проект может использоваться для:
-
личной базы знаний;
-
хранения идей и голосовых заметок;
-
анализа переписки;
-
поиска информации по проектам;
-
сохранения договорённостей;
-
работы с документами;
-
подготовки отчётов;
-
контроля задач;
-
корпоративной базы знаний;
-
AI-ассистента для бизнеса.
Главная ценность системы — возможность быстро получить ответ из собственных данных, не тратя время на ручной поиск по почте, файлам, заметкам и документам.
Вывод
“Электронный мозг” — это не просто хранилище файлов или заметок. Это AI-платформа, которая помогает превращать повседневную информацию в управляемую базу знаний.
Голосовые записи, письма, документы и облачные файлы становятся частью единой памяти, с которой можно общаться через GPT.
Такой подход особенно полезен предпринимателям, специалистам, командам и всем, кто работает с большим объёмом информации и хочет быстро находить нужные данные в своих материалах.